Dec 22, 2025
Metadata Systems

Unstructured Data Processing
ETL Pipeline from PDFs to Dataset
Key Results
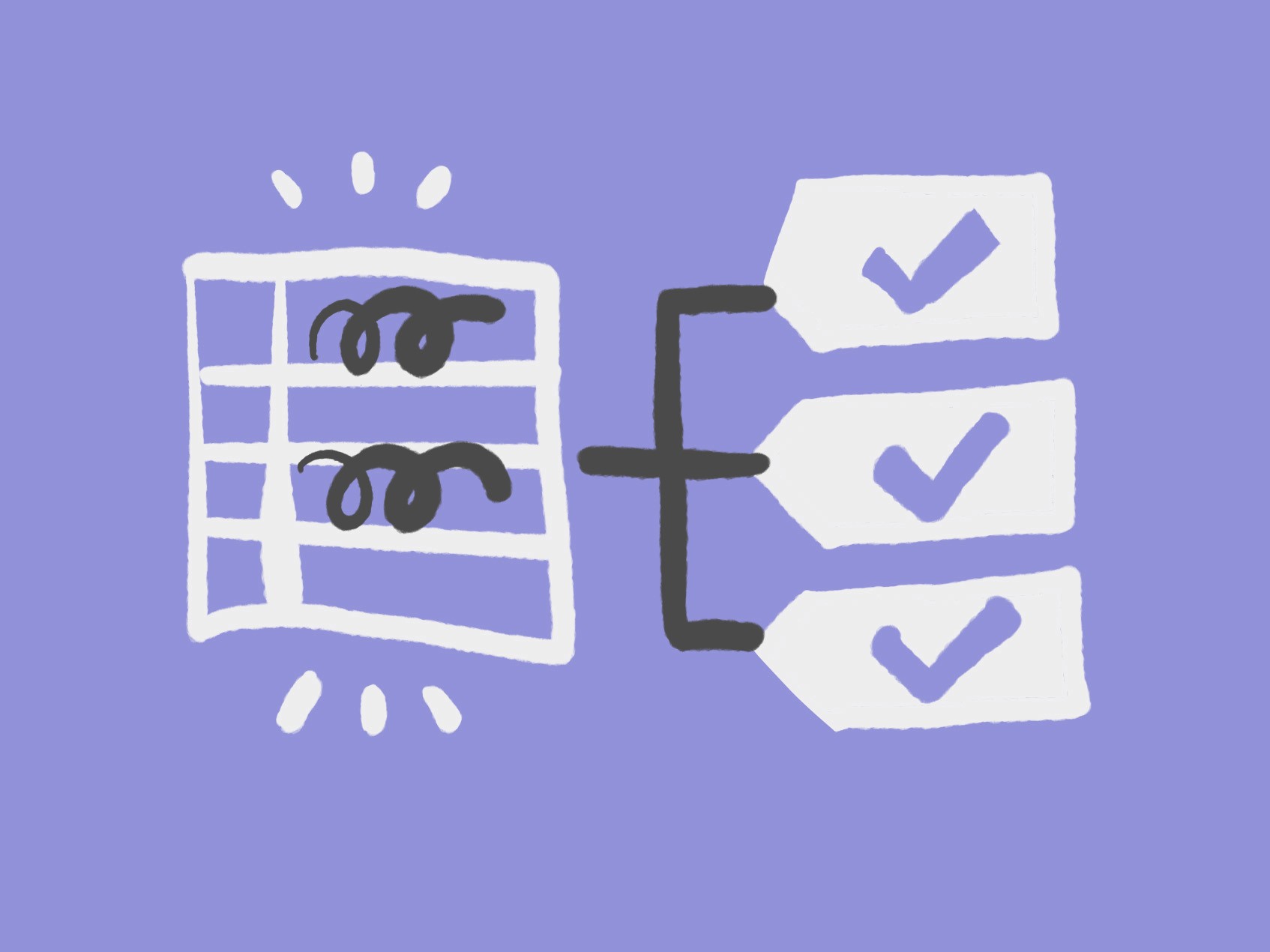
816 rows from 5 PDFs → 1093 rows from 2 Normalized datasets
50+ category → 9 controlled categories (82% reduction)
81% biographical enrichment via validated Google API integration
Role & Timeline
Data Engineer
Fall 2024 (14 weeks)
5 years (1950-1955) extracted from MoMA Archives
MoMA Archive Public-access catalog PDF
Approach
ETL (Extract, Transform, Load)
Python (pandas, regex, requests)
OpenRefine
Semi-automated wth validation gates
The Challenge
When the tools don't exist, build them.
As an academic researcher studying MoMA's Good Design Exhibition (1950-55), I only have five scanned catalog PDFs for analysis available from the MoMA Good Design website page and archive. I know what tools I need, but none are available: no open-source catalog PDF-to-CSV dataset tools, no structured fields or metadata for exhibition analysis, and no data enrichment options.
Original Optical Character Recognition-scanned catalog where the data was shaped initially. Source: Long Version: The Museum of Modern Art Exhibition Records, 463.19., 494.8., 520.11., 542.4., 570.1.,The Museum of Modern Art Archives, New York. (left) and an enriched analytic dataset as original_catalog.csv (right). Author's copyright.
Data state blocks
OCR issues on variant spellings, e.g., “Arundall Clarke” vs. “Arundell Clarke.”
6–12 category variations per year, preventing systematic comparison
Zero biographical context for the entities for both designers or organizations (nationality, gender, birth/death missing)
Discovery
Design Decision 1#
Semi-Automation Over Full Automation
Accuracy Confidence over The Processing Speed
Data Normalization
Implemented name normalization to identify and merge aliases for each designer (e.g., spelling variants and OCR errors) using OpenRefine clustering—ideal for messy data. This supports OCR automation and mitigates human-like data-entry errors.
Data Enrichment Strategy
The initial dataset extracted from the catalogs included no designer biographical information, yet the analysis required gender, region, and age at the time of exhibition. These became core data fields. Python extraction includes data provenance to improve confidence scoring. The code flags uncertain entries (<95% confidence) for manual review; ~5% of entries required semi-automated validation.
To handle the volume, I designed a priority-based semi-automated workflow.
Focus manual effort: high-priority designers received multi-source validation (MoMA database, Wikipedia, library catalogs, Google search).
Track provenance: added a source field documenting data origin (Known Database, Wikipedia, Not found, Name inference).

Strategic resource allocation over a blanket approach: 2 days of semi-automated work focusing on 50+ high-impact designers vs. weeks for perfect coverage of all 276 names (including obscure single-item contributors). Quality gates plus provenance tracking provide transparent data credibility.
81% enrichment rate with documented sources. The remaining 19% is explicitly flagged as "Not found" or "Name inference"; gap transparency enables honest analysis.
Design Decision 2#
Reorganizing exhibition Categories with better Taxonomy


Here is a snippet of the data viz based on this normalization, preserves and improves. Analytical value.
Data Visualization for Item Contribution based on Designers' Gender

Project Outcomes
Framework applicable to museum collections, research institutions, cultural heritage datasets. Anywhere historical catalogs need digitization and data interoperability.
ETL Workflow
Extract, Standardize, Enrich
Semi-automated: algorithms suggest, humans validate. Python + OpenRefine + Google API.
Taxonomy Design
82% reduction
+32 categories → 9 controlled categories. Hierarchical classification, semantic validation, scope definitions, and preventing ambiguity.
Data Transformation
81% biographical enrichment
Priority-based workflow: high-impact designers (3-19 items) = multi-source validation, low (1 item) = automated.
Quality Framework
Data provenance /record
Completeness metrics documented (48-100% range). 52% gaps explicit—absence reveals preservation priorities.
Reflection & Learning
This is an independent research project for a class, and it was extended to the Data Visualization Mentorship program by the DataViz Society.
Data source: Cleaned from publicly available PDF catalogs, enriched via Google API & Wikidata—not MoMA internal records. Further development would benefit from institutional collaboration.
Quality considerations: Semi-manual verification may introduce errors in edge cases. Fuzzy name matching set at >80% confidence threshold—tradeoff between automation and accuracy.
DISCLAIMER
Data Source: The Museum of Modern Art Exhibition Records: 463.19, 494.8, 520.11, 542.4, 570.1. The Museum of Modern Art Archives, New York. Note: Manual data extraction may contain errors and may not fully reflect internal information resources. Personal class project for Data Visualization; additional archival materials not yet consulted. Feedback welcome.

Learn More

This dataset also supports network graph exploration. The dataset comprises 111 designers from 17 countries, 62 schools, and seven art movements, from the same dataset for the Map Visualization, but enriched with nodes.
Table of Contents